Purpose, Argument, Streams, Usage, Examples, Related
┌─NOPAD────┐
>>──COLLATE──┼──────────┼──┤ Group ├─────────────────────────────────────────────────><
└─PAD─char─┘
Group:
┌─1-*─────────────1-*────────────┐ ┌─MASTER DETAILs─┐
├──┼────────────────────────────────┼──┼────────────────┼─────────────────────────────┤
└─columnrange1──┬──────────────┬─┘ ├─MASTER─────────┤
└─columnrange2─┘ ├─DETAILs────────┤
└─DETAILs MASTER─┘
Notes:
(1) columnrange1 and columnrange2 are unsigned.
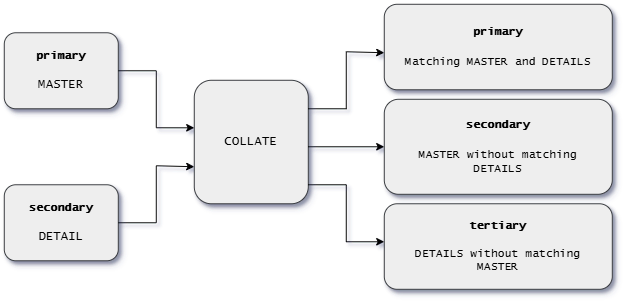
Use the COLLATE stage to match records in its primary input stream with records in its
secondary input stream and write the matched and unmatched records to different output
streams. The records in each input stream must be in ascending order based on the contents
of a key field.
The records in the primary input stream are referred to as MASTER records. Each MASTER
record has a key field; a specific range of columns within a record with unique contents
that identifies the record. Two MASTER records cannot have the same contents in their key
field.
The records in the secondary input stream are referred to as the DETAIL records. The DETAIL
records have key fields as well and both the MASTER and DETAIL records should be sorted in
ascending order by their key fields. A DETAIL record matches a MASTER record when the key
field in both records contains the same data. Two or more DETAIL records can have the same
data in their key field.
COLLATE writes records to three output streams if each is connected:
**** Top of file **** Address Rxpipe
'pipe (endchar ?)', '< master.txt', /* Read MASTER records. */ '| c: collate', /* Find matches. */ '| > matching-records.txt', /* Write matching MASTERs and DETAILs. */ '?', '< details.txt', /* Read DETAIL records. */ '| c:', /* Define secondary stream for COLLATE. */ '| > unref-masters.txt', /* Write MASTERs without DETAILs. */ '?', 'c:', /* Define tertiary stream for COLLATE. */ '| > unref-details.txt' /* Write DETAILs without MASTERs. */
Exit 0 **** End of file ****
account.txt (input)
...|...+....1....+....2....+....3....+....4....+.... **** Top of file **** 1 Alfred, John Account Number: 22222 2 Conners, Steve Account Number: 98989 3 Miller, Mike Account Number: 34567 4 Niles, Patrick Account Number: 11188 5 Smith, Andrew Account Number: 54545 6 Smith, Justin Account Number: 77777 7 Williams, Janice Account Number: 88444 **** End of file ****
account-type.txt (input)
...|...+....1....+....2....+....3....+....4....+.... **** Top of file **** 1 Alfred, John Checking £ 350.00 2 Alfred, John Savings £1,300.00 3 Alfred, John Money Market £9,000.00 4 Conners, Steve Savings £ 50.00 5 Smith, Andrew Savings £1,999.00 6 Smith, Andrew Money Market £9,999.00 7 Smith, Justin Checking £ .50 **** End of file ****
**** Top of file **** Address Rxpipe
'pipe (endchar ?)', '< account.txt', /* Read account.txt. */ '| c: collate 1-19 master detail', /* Match the records. */ '| > all-accounts.txt', /* Write matching MASTER and DETAIL.. */ , /* ..records to all-accounts.txt. */ '?', /* Start of the second pipeline.. */ '< account-type.txt', /* Read account-type.txt. */ '| c:' /* Define secondary input for COLLATE. */
Exit 0 **** End of file ****
all-accounts.txt (output)
...|...+....1....+....2....+....3....+....4....5.... **** Top of file **** 1 Alfred, John Account Number: 22222 2 Alfred, John Checking £ 350.00 3 Alfred, John Savings £1,300.00 4 Alfred, John Money Market £9,000.00 5 Conners, Steve Account Number: 98989 6 Conners, Steve Savings £ 50.00 7 Smith, Andrew Account Number: 54545 8 Smith, Andrew Savings £1,999.00 9 Smith, Andrew Money Market £9,999.00 10 Smith, Justin Account Number: 77777 11 Smith, Justin Checking £ .50 **** End of file ****
**** Top of file **** Address Rxpipe
'pipe (endchar ?)', '< account.txt', /* Read account.txt. */ '| c: collate 1-19 detail', /* Match the records. */ '| > balance.txt', /* Write matching DETAIL records. */ '?', /* Start of second pipeline.. */ '< account-type.txt', /* Read account-type.txt. */ '| c:', /* Define secondary streams for COLLATE. */ '| > no-account-type.txt' /* Write unmatched MASTER records. */
Exit 0 **** End of file ****
balance.txt (output)
...|...+....1....+....2....+....3....+....4....5.... **** Top of file **** 1 Alfred, John Checking £ 350.00 2 Alfred, John Savings £1,300.00 3 Alfred, John Money Market £9,000.00 4 Conners, Steve Savings £ 50.00 5 Smith, Andrew Savings £1,999.00 6 Smith, Andrew Money Market £9,999.00 7 Smith, Justin Checking £ .50 **** End of file ****
no-account-type.txt (output)
...|...+....1....+....2....+....3....+....4....+....5.... **** Top of file **** 1 Miller, Mike Account Number: 34567 2 Niles, Patrick Account Number: 11188 3 Williams, Janice Account Number: 88444 **** End of file ****
**** Top of file **** Address Rxpipe
'pipe (endchar ?)', 'in', /* Connection from CALLPIPE. */ '| split', /* Split records at blanks and discard them. */ '| sort unique', /* Sort records and discard duplicates. */ '| c: collate', /* Match records. */ '?', /* Start of second pipeline.. */ '< stopwords.txt', /* Read stopwords.txt. */ '| c:', /* Define secondary streams for COLLATE and.. */ , /* ..write unmatched MASTER records to secondary.. */ , /* ..output of COLLATE */ '| out' /* Connect back to CALLPIPE. */
Exit 0 **** End of file ****